Handling Fatal Errors in Production on a Saturday Night
The tale of a tricky bug and the tools used to quicky find and fix it
Background
In my last post I described the way we instrumented all our AWS Lambda functions on hamiltix.net so any unhandled error was sent as a Pushover notification with a full stack trace. While some were concerned this would lead to a flood of messages, it has been nearly silent except for purchase notifications and a few minor bugs which were corrected. Everything had been running smoothly for a while, until...
The Error
It was Saturday, 8:21 P.M. I'd just returned home when I got a Pushover notification.
![[FATAL] Error in TheMoneyLambda](images/handling-fatal-errors-in-production-on-a-saturday-night/pushover.jpeg)
The few error notifications we have gotten are in a query or other part of the website that is a "first step" of the user experience. By the time a user gets to the point where they are interacting with "TheMoneyLambada" the order is complete (hence the name). What this means is that a user was trying to purchase tickets when this occurred. Priority: Critical.
I sit down at my laptop and open the CloudWatch dashboard. All Lambda standard out or logging messages are captured by CloudWatch, so this should show exactly what caused the error. Immediately I saw the error, "Invalid Ticket Group Quantity." Like all tricky bugs I immediately thought, "That's impossible!" The details of the order are all checked with the broker immediately before purchase. TheMoneyLambda should never be handling an order that hasn't been checked for correctness. The check is handled by a separate lambda, so flipping over to those logs I see that it was checked successfully. About this time I get another error notification, same as first. Worried the customer is getting error messages and attempting to buy the tickets multiple times, I fire off a quick email (captured at checkout) to them letting them know I am looking into the issue.
The pressure was on now. I have no idea how this bug was possible and I'm about to loose a customer. With a grand total of $0 spent on marketing, word of mouth and this blog is the only driver of sales. A bad customer experience could torpedo the whole project.
The Secret Weapon
With the contradiction of the Lambda logs leading no where, I turned to a tool that I added to the site more for fun than anything. LogRocket is a javascript snippet that you can add to any page and it hooks user interactions and logging and presents it back in a timeline view. From time to time I would use it to see how people interacted with the site (my friend calls this "watching film" - like we are a sports team). While we include LogRocket on the checkout page, we explicitly tell it NOT to capture any of the credit card fields. In the renders they just don't appear (as if the element was deleted) which keeps us from accidentally storing any payment data.
In LogRocket I pick out the session right away and watch the user interaction from the beginning. Every thing looks normal, except the ajax calls to API Gateway (and therefore Lambda) fail. Then I see it. LogRocket helpfully captures all the details about ajax calls, and I notice the duration is about 15 seconds.
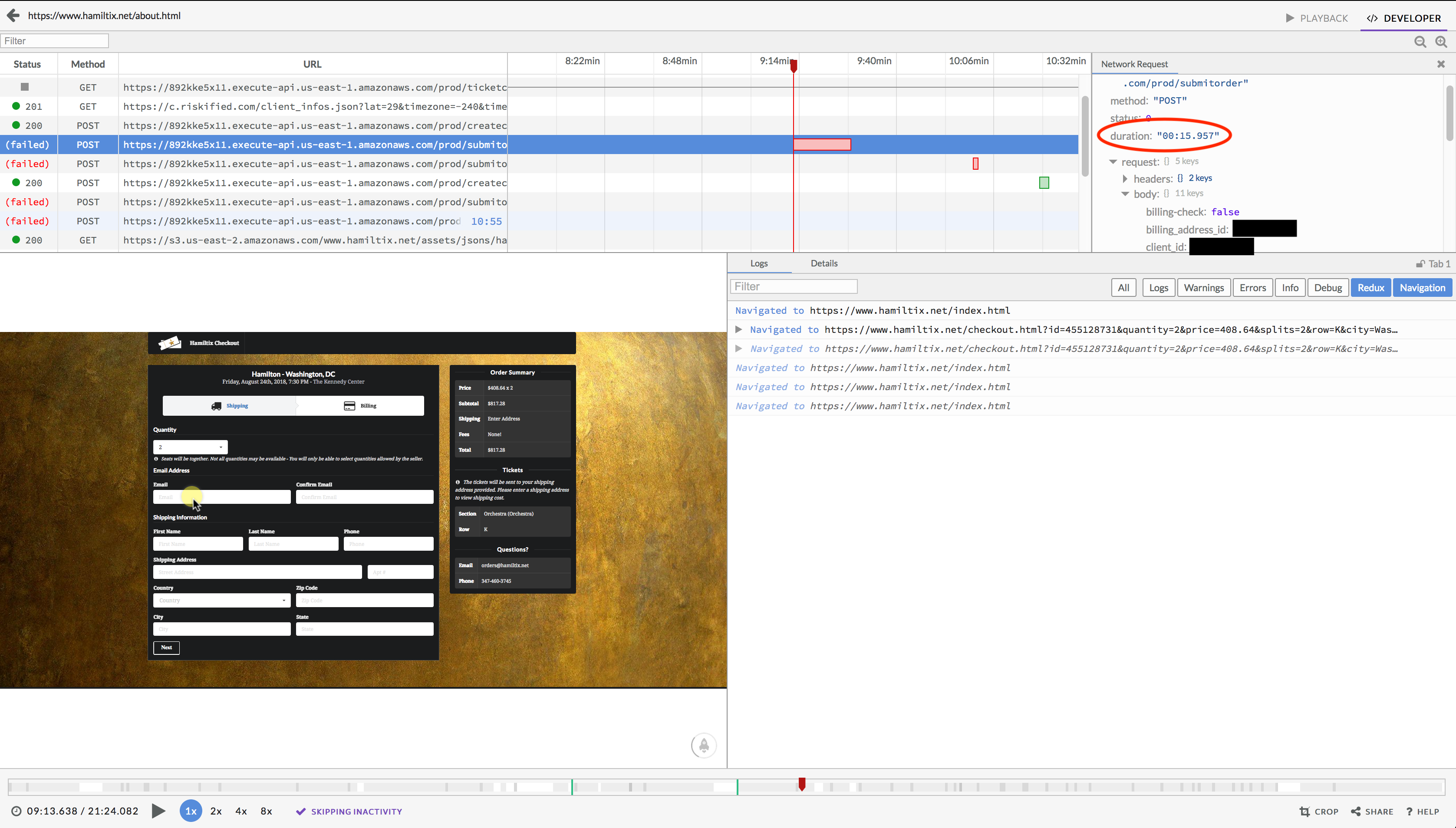
Besides being an eternity online, 15.957 seconds is awfully close to the default 15 seconds execution limit on Lambada functions. Switching back to the CloudWatch logs I scroll up past the two errors I initially fixated on to see this:
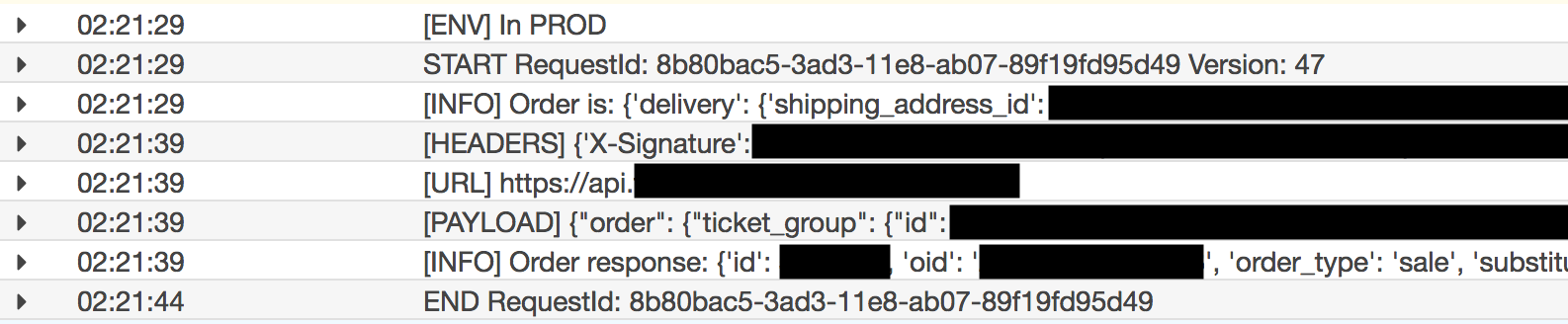
No errors, no traceback. Apparently a successful order. In my initial haste to find the issue I was focused on the errors and missed the fact they were preceded by a successful order. The function must have timed out just before sending the successful order notification and returning a 200 status to the front end. For some reason the broker's API took ten seconds to respond, which in turn caused our Lambda function to hit its time limit of 15 seconds, but not before actually processing the order! The user saw an error on the site, while at the same time getting a confirmation email. I communicated the issue to the customer, who was really great about everything, and immediately increased the execution time limit for TheMoneyLambda. With Lambda aliases, you have to make the change in the Lambda's dashboard then push a new version to all aliases you want changed. This prevents you from accidentally changing a parameter or environment variable that a current alias requires when updating a function. With the GitLab pipelines described in my previous post its as simple as re-running the deploy stage.
If the broker API had failed completely, or was a little faster this error wouldn't be possible. It was just slow enough to succeed on the back end while failing on the front end.
Lessons Learned
- Instrumenting business critical functions to receive instant error notification is key to knowing there is a problem.
- Quick communication with affected customers can help smooth over an otherwise bad experience.
- During testing, ensure you test less-than-optimal conditions to include very slow responses.
- Sometimes the stars align to serve you a tricky bug on a Saturday night. Welcome to the startup life =)
In the market for Hamilton the Musical tickets? Find a better ticket search, alert, and buying experience at hamiltix.net.
Questions or comments? blog (at) badsectorlabs.com